Also could have been called “The things that probably should have been more obvious to me regarding software vulnerabilities than they ended up being.” I’ve spent more time than I’d prefer to admit trying to wrap my head around some of these concepts, so maybe this will help someone else.
From the perspective of gathering scan results and acting on them for the benefit of the orgainzation.
Common Vulnerabilities and Exposures (CVE) 🔗
TL;DR: Public catalog of software vulnerabilities.
CVEs are the backbone of talking about software vulnerabilities. This is essentially public numbering system and catalog to give us all a single point of reference when talking about a vulnerability. So instead of every vulnerability needing its own special name, such as Log4Shell, the vulnerability in Log4J from December 2021, we can reference CVE-2021-44228, and we all know we’re talking about the same vulnerability.
I’m not going to assume I know the history of the CVE system or how they get created, and ultimately for my role, I’m not very interested in understanding this. However, I felt overwhelmed trying to understand where to look for “source material,” and therefore I think it’s useful to know a couple key names you’ll encounter when researching a vulnerability and their role:
- MITRE Corporation maintains the CVE system. While there are several CVE Numbering Authorities (CNAs), I think MITRE is the coordinating entity.
- The National Vulnerability Database (NVD), is what many auditing bodies, especially from the government, expect to see your data sourced from. NVD enriches the CVE data, generally with CVSS, CWE, and CPE.
NVD is the common source for CVE data and enrichment (for now), and for some auditing bodies, such as FedRAMP, it’s required to source NVD data. If you need information about a CVE, NVD should usually be your first stop, although it’s imperfect.
There is a specification for how to define a CVE. Check the github repository for the JSONSchema and documentation.
General CVE resources:
- cve.org, what appears to be the new version of cve.mitre.org.
- CVE Program on Github.
- CVEs and the NVD Process.
Common Vulnerability Scoring System (CVSS) 🔗
TL;DR: Metrics for scoring vulnerability severity.
CVSS provides a set of metrics to analyze a vulnerability by, and formulas to derive a score from those metrics. Severity can then be derived from the CVSS score. CVSS gives a numeric score, which then often gets translated to a Severity level, typically on scales such as High, Moderate, and Low, or sometimes bookending those with Critical and Informational.
All current versions of CVSS have a “Base” score, which is what is frequently provided by NVD, and has other categories of metrics which are left to be completed by the end user to provide environmental context to a CVE. Please be sure to read the next section on Severity vs. Risk before getting carried away with the Base score. It is very important to add your context to a vulnerability before prioritizing action on it.
CVSS is defined by the CVSS Special Interest Group (SIG) on first.org. You can find the specification, user guides, calculators, and archived versions of CVSS on the first.org website.
Severity vs. Risk (IMPORTANT) 🔗
TL;DR: Always add context on top of the base CVSS score.
Severity does not equal risk! DO NOT PRIORITIZE CVES BY LOOKING AT THEIR BASE CVSS SCORE!
Obviously when evaluating “how bad” something is, getting a 10/10 must be really bad. And when it’s called a critical vulnerability, how can you not run screaming? It gets worse when there’s colors attached to them, where green == good, and red == bad.
That’s the exaggerated gut reaction you might have when you encounter CVSS and Severity for the first time, which is unfortunate. I can say that with confidence, because this is how I categorized “how bad” a vulnerability was before I got more involved with vulnerability management. It’s such a common misunderstanding, in fact, that NVD’s Vulnerability Metrics page notes this in the second sentence, and the CVSS 4.0 User Guide dedicates a whole subsection to clarifying this (2.2).
Regarding the Base CVSS score from NVD, there’s a couple things to bear in mind:
- It can take some time from the day a CVE number is assigned to a vulnerability before NVD can enrich it with a score.
- The CVE and CVSS can be modified over time, as more data becomes available, or as other parties are consulted to understand the vulnerability.
- There can be disagreement regarding the base score, and ultimately we’re often stuck (with reporting bodies that require NVD data) with what NVD decides to go with.
Daniel Stenberg, the curl maintainer, has ranted about this issue several times, which I feel are worth the time to read:
Prioritizing based on CVSS 🔗
CVSS is not without its use, but it’s important not to take the base scores provided at face value.
The current version of CVSS is 4.0. With each version has come more ways to add context to a CVE to understand your actual risk. A failure to add this context will result in a false understanding of what you’re most likelye affected by.
Only after you have contributed your contextual values to the available metrics can you consider using the score as a value to prioritize the risk level of a vulnerability to your system.
Common Weakness Enumeration (CWE) 🔗
TL;DR: Vulnerability classification system.
CWE is a classification system which defines the type of a vulnerability. It’s defined as a tree, so you can get more or less granular in your description of what type a vulnerability is. NVD uses CWE to help score build a CVSS score.
I find CWE helpful for discussing a vulnerability, but given my primary concern of gathering and reporting vulnlerabilities, not that useful. If NVD wasn’t already considering CWE as a part of their CVSS scoring, then I might look closer, but that’s already in use when calculating the base score. So I don’t concern myself with CWE for my automations.
- MITRE Page. MITRE maintains CWE, and you can find a list of CWEs there.
- NVD Page with definition and their usage.
Common Platform Enumeration (CPE) 🔗
TL;DR: Standardized product naming scheme.
CPE is a standard naming scheme to identify a product such as software package. It’s not the only standard, and not the modern way, but it’s what you get from CVE for now. The NVD CVE pages sometimes have a list of CPEs to list the software configurations containig a CVE. I think scanners might use this data, but I don’t think that these CPE lists are complete enough to be usable for my purposes. I’ll rely on scanners to identify vulnerable packages for me.
NIST provides a dictionary (database) of official CPE names.
If standard naming schemes are of interest to you, I’d encourage learning purl instead.
Tom Alrich has a lot to say on the matter:
Scanners 🔗
Identifying Vulnerable Packages 🔗
TL;DR: Always list the package containing a vulnerability beside the CVE.
The CVE alone, particularly from NVD, is often not enough information to act on. This is a mistake that took me longer than it should have to realize the importance of. My perspective had been “Auditors only care THAT a CVE is present, so that’s all the information that we need.” But as soon as I was asked to help remediate some of the vulnerabilities I was reporting on, I noticed that more information is necessary. To know how to remediate a found vulnerability, we need to know WHERE the CVE is present.
Take, for example, the vulnerabilities in Log4j. Log4j is a Java library used
by other applications. You won’t be able to use find on your system to go
find the Log4j file and update it. Rather, you need to know all of the software
on your system which builds Log4j into the application, and then go update each
of those softwares to versions that built a different version of Log4j into it.
This is information that the scanner ought to be providing to you, so don’t
dump it just because you have a CVE ID!
This also means you can have multiple instances of the same vulnerability on a single system. You might have multiple pieces of software on your system which were all built with the vulnerable version of Log4j, and scanners should be reporting to you each instance of that vulnerability for each software it’s found in.
This seems to me like it’s the role of CPE, but Log4j is used everywhere. Look at the CPE list on the NVD CVE page for Log4j - there’s a ton listed, and it’s certainly non-exhaustive. And it doesn’t necessarily tell you what version to update to in order to resolve it. I don’t know how CPE could give me enough information all alone to be able to know how to remediate the CVE on a system. I need to know which package contains the CVE, and even better if I also learn from the scanner where on a system that package is located.
Your scanner should tell you which package it finds with a vulnerability on it. But how does the scanner know this information? Probably from reading security advisory databases.
For example, the major Operating Systems will put out advisories for packages
it publishes. Here is Red
Hat’s,
which get IDs beginning with RHSA-. Github posts vulnerabilities it
originates with the prefix GHSA-.
OSV is an aggregation for vulnerabilities from various
package managers advisories.
If you want to understand more about how scanners collect the information they’re reporting to you, I found reading through the Trivy DB to be an insightful endeavor.
CVE Grouping 🔗
TL;DR: List all of the vulnerabilities for a given package together.
It’s pretty normal for scanners to group CVEs by the package they’re found on, and that’s something that, when reporting to others, you should carry on. It can massively reduce the shock factor of how many CVEs are present on a system, if you can, rather, first identify the vulnerable packages.
Here’s an example from Nessus Plugin 205638, which reports seven CVEs on a single version of Thunderbird in Fedora 39.
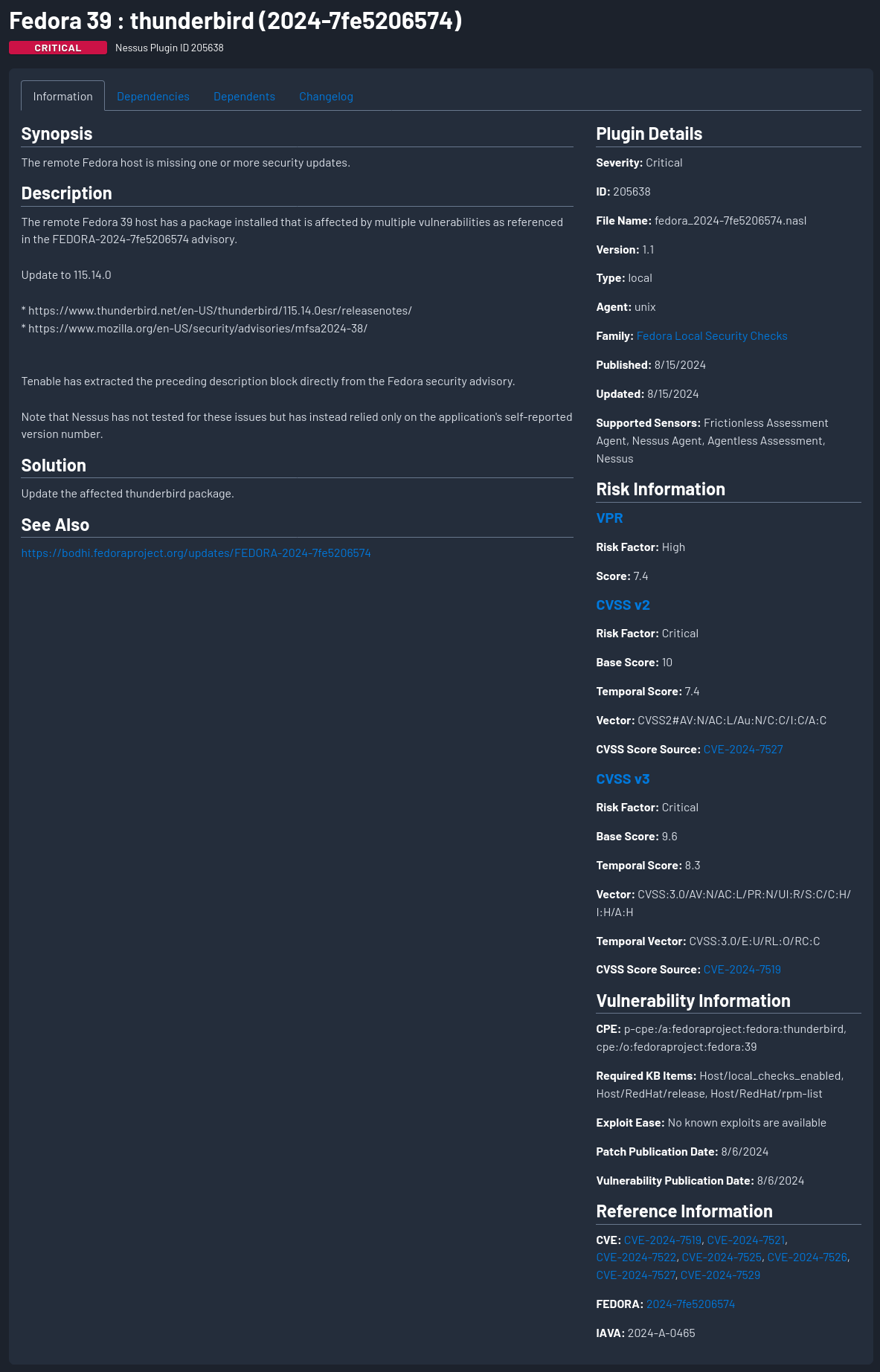
Typically, I feel that you should still evaluate each CVE in a vulnerable package, adding context individually and not as a group. I mention this because I was confused the first time I encountered a Nessus vulnerability, which listed a dozen CVEs, but only provided CVSS scoring for the group once.
I recall once evaluating all of the CVEs in the group from a Tenable page like this, and none of them had the same data as what this page was telling me about the group, so I made an assumption then that Tenable was creating their own score based on the group of CVEs. Now, I see that the page lists the CVSS Score Source as being just one of the CVEs, which I assume is the CVE with the highest CVSS score.
I don’t think that source used to be listed, and it was quite possibly a bug or misunderstanding in an older view of this screen that caused me some confusion. But that confusion led me to conclude that I will always evaluate each CVE in a package individually, even though I’ll group them all together in reporting.
As an example, for a given system, I imagine the hierarchy like this:
.
├── packageA
│ ├── CVE-2024-1234
│ ├── CVE-2024-5678
│ └── CVE-2024-9012
└── packageB
├── CVE-2024-1234
├── CVE-2024-5678
└── CVE-2024-9012
Where a single system has two packages, and there is overlap in which CVEs each package has (they’re identical in this because I’m too lazy to come up with more). Since they’re part of the same system, I might apply the same context to identical CVEs on the same system, but I will still report it as part of both packages, because I need to know which packages must be updated in order to remediate a CVE entirely from my system.
Remediation 🔗
I’m of the opinion that it’s feasible to run a system that has zero CVE’s reported on it by a normal scanner. However, it takes effort to accomplish this.
I think it’s a simpler story, both for scanning and maintaining clean systems, if you can run immutable infrastructure. Scanning a static image is a simple action, and gives you the opportunity to clean up the image in an isolated environment and test your software on it before redeploying. That’s opposed to patching running instances and hoping it doesn’t break compatibility with your software.
This is cheap and easy with container images, as a container should ideally be a packaging mechanism containing only the minimal libraries needed to run your application. Google’s distroless images and Chainguard’s images make it very easy to get a minimal base image, which makes your primary responsibility to not add vulnerable packages to the base image.
It’s a marginally larger amount of work to do the same thing for virtual machines, but still not very difficult to produce a CVE-free machine image and add your software to it.
Sprinkle some SAST into your CI/CD pipelines to make sure the artifacts you produce aren’t using vulnerable libraries, and you should mostly be on your way.
I’m aware it’s not always this simple, but I think it’s not out of the question, and worth persuing.
Fin 🔗
Hope that helps someone.